RabbitMQ docker 运行
docker run -d -p 15672:15672 -p 5672:5672 --hostname rabbit --name rabbit -e TZ=Asia/Shanghai -e RABBITMQ_DEFAULT_USER=admin -e RABBITMQ_DEFAULT_PASS=admin rabbitmq:3-management- 5672端口:RabbitMQ 的端口
- 15672端口:RabbitMQ web 端管理工具的端口
- RABBITMQ_DEFAULT_USER:RabbitMQ 登录的用户名
- RABBITMQ_DEFAULT_PASS:RabbitMQ 登录的密码
- TZ: 设置容器的时区
启动成功后,访问localhost:15672即可访问管理界面,可以看到这是一个简单的单节点rabbitmq
RabbitMQ docker 集群搭建
复制
所有 RabbitMQ 操作所需要的数据/状态需要复制到所有的节点上。一个例外是消息队列,默认只存在于一个节点,虽然他们可以在所有节点上访问到。要复制队列到所有节点上,请查看 高可用 文档。
主机名解析要求
RabbitMQ 节点通过域名来互相访问,因此集群中的所有节点能够互相访问域名。域名解析可以使用任何标准的 OS-provided 方式:
- DNS 记录
- 本地文件(如
/etc/hosts)
在严格的环境中,DNS记录或主机文件修改受限制,Erlang VM可以配置为使用备用主机名解析方法,例如备用DNS服务器,本地文件,非标准主机文件位置,或混合的方法。这些方法可以与标准的OS主机名解析方法一致。
集群生成
集群可以用多种方式生成:
- 用
rabbitmqctl人为生成(例如在开发环境) - 在 配置文件 中声明集群节点
- 通过 rabbitmq-autocluster (一个插件)来构建
群集的组成可以动态地改变。所有 RabbitMQ 开始运行在单个节点上,这些节点可以连接成群集,然后再次转回单个节点。
故障处理
RabbitMQ 容忍单个节点的失败。节点可以随意启动和停止,只要他们可以联系在关机时已知的成员节点
磁盘和内存节点
一个节点可以是硬盘节点(disk node)或内存节点(RAM node)。大多数情况下你想要所有的节点都是硬盘节点;内存节点是一个特殊的情况,可以用于提高集群的性能,当有疑问时,使用硬盘节点。
节点间的验证
RabbitMQ 节点和客户端工具(如 rabbitmqctl)使用 cookie 来检测节点间是否允许交流。对于两个能够互相交流的节点来说,他们必须有相同的 Erlang cookie。这个 cookie 只是一个字母组成的字符串。只要你喜欢,它可以很短。每一个集群节点都应该有相同的 cookie。
当 RabbitMQ 服务启动时,Erlang 虚拟机会自动创建一个随机的 cookie 文件。最简单的方法是允许一个节点创建该文件,然后将该文件复制到其他所有节点。
在 Unix 系统中,cookie文件一般存在于/var/lib/rabbitmq/.erlang.cookie或$HOME/.erlang.cookie。
集群记录
手动部署
启动独立的节点
通过将已存在的 RabbitMQ 节点重新配置到集群中来生成集群。第一步是在所有节点上以正常方式启动 RabbitMQ:
docker run -d -p 15672:15672 -p 5672:5672 --hostname rabbit --name rabbit -e RABBITMQ_DEFAULT_USER=admin -e RABBITMQ_DEFAULT_PASS=admin rabbitmq:3-management docker run -d --hostname rabbit-slave1 --name rabbit-slave1 -e RABBITMQ_DEFAULT_USER=admin -e RABBITMQ_DEFAULT_PASS=admin rabbitmq:3-management docker run -d --hostname rabbit-slave2 --name rabbit-slave2 -e RABBITMQ_DEFAULT_USER=admin -e RABBITMQ_DEFAULT_PASS=admin rabbitmq:3-management复制cookie文件
docker cp rabbit:/var/lib/rabbitmq/.erlang.cookie . docker cp .erlang.cookie rabbit-slave1:/var/lib/rabbitmq/ docker cp .erlang.cookie rabbit-slave2:/var/lib/rabbitmq/重启修改过cookie的节点
docker restart rabbit-slave1 docker restart rabbit-slave2修改
/etc/hosts文件,将以下内容写入所有节点的/etc/hosts文件:172.17.0.2 rabbit rabbit 172.17.0.3 rabbit-slave1 rabbit-slave1 172.17.0.4 rabbit-slave1 rabbit-slave1查看当前所有节点的集群状态:
rabbitmqctl cluster_status将rabbit-slave1节点加入集群,在rabbit-salve1上执行:
rabbitmqctl stop_app rabbitmqctl join_cluster rabbit@rabbit rabbitmqctl start_app加入集群会隐式复位节点,从而删除先前在该节点上存在的所有资源数据。
将rabbit-slave2节点加入同一个集群,在rabbit-slave2上执行:
rabbitmqctl stop_app rabbitmqctl join_cluster rabbit@rabbit-slave1 rabbitmqctl start_app我们选择将rabbit-slave2加入rabbit-slave1节点,这里演示了选择哪个节点无所谓,提供一个在线的节点就足以将新节点加入集群。
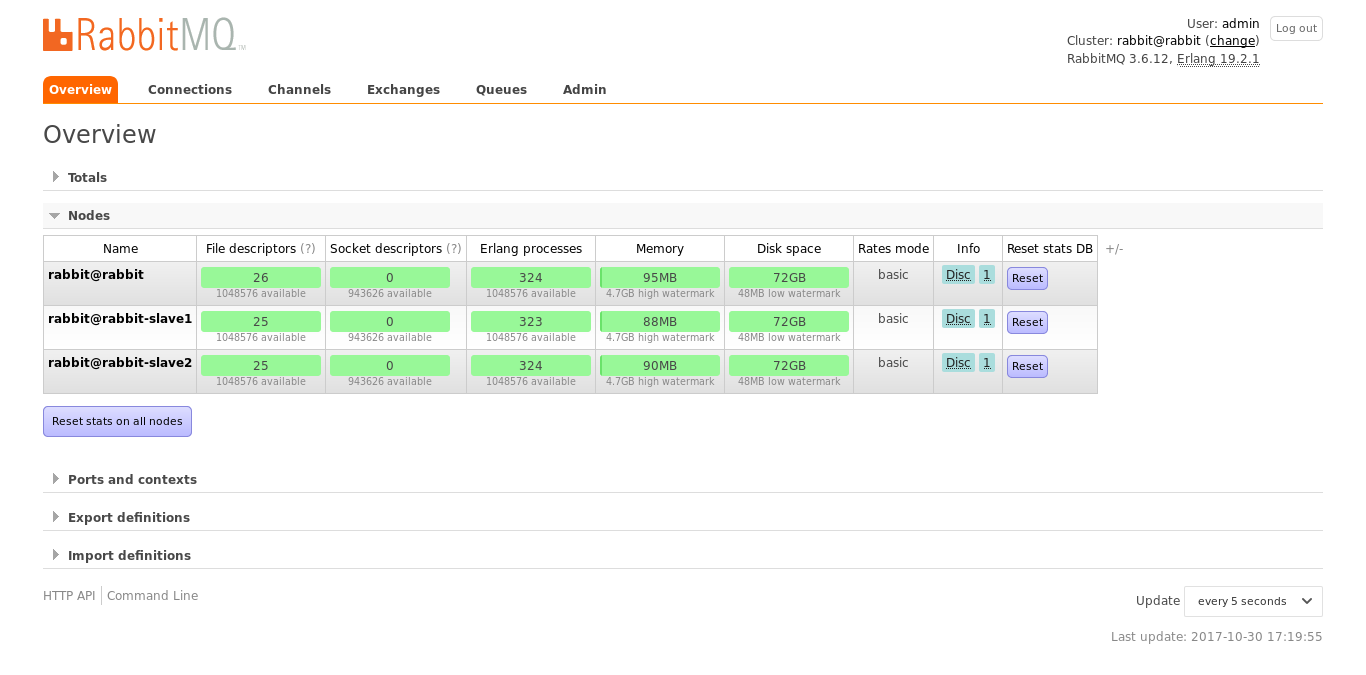
再次查看集群状态,应该可以看到集群中有三个节点:
root@rabbit:/# rabbitmqctl cluster_status Cluster status of node rabbit@rabbit [{nodes,[{disc,[rabbit@rabbit,'rabbit@rabbit-slave1', 'rabbit@rabbit-slave2']}]}, {running_nodes,['rabbit@rabbit-slave2','rabbit@rabbit-slave1',rabbit@rabbit]}, {cluster_name,<<"rabbit@rabbit">>}, {partitions,[]}, {alarms,[{'rabbit@rabbit-slave2',[]}, {'rabbit@rabbit-slave1',[]}, {rabbit@rabbit,[]}]}] root@rabbit:/#或者进入网页管理界面也可以看到三个节点在集群中:
通过配置文件部署
配置文件示例
cluster-rabbitmq.conf:loopback_users.guest = false listeners.tcp.default = 5672 hipe_compile = false cluster_partition_handling = pause_if_all_down cluster_partition_handling.pause_if_all_down.recover = autoheal cluster_partition_handling.pause_if_all_down.nodes.1 = rabbit@rabbitmq-node1 cluster_partition_handling.pause_if_all_down.nodes.2 = rabbit@rabbitmq-node2 cluster_partition_handling.pause_if_all_down.nodes.3 = rabbit@rabbitmq-node3 cluster_formation.peer_discovery_backend = rabbit_peer_discovery_classic_config cluster_formation.classic_config.nodes.1 = rabbit@rabbitmq-node1 cluster_formation.classic_config.nodes.2 = rabbit@rabbitmq-node2 cluster_formation.classic_config.nodes.3 = rabbit@rabbitmq-node3 cluster_formation.node_type = disc collect_statistics = fine通过容器启动三个rabbitmq节点,启动容器脚本:
#!/bin/bash
docker run -d \
-h rabbitmq-node1 \
-e TZ=Asia/Shanghai \
-e RABBITMQ_ERLANG_COOKIE='helloworld' \
-v $HOME/Docker/rabbitmq/conf/cluster-rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf \
-v $HOME/Docker/rabbitmq/data/node1:/var/lib/rabbitmq/mnesia:rw \
--add-host rabbitmq-node1:172.17.0.3 \
--add-host rabbitmq-node2:172.17.0.4 \
--add-host rabbitmq-node3:172.17.0.5 \
--name rabbitmq-node1 \
rabbitmq:3-management
docker run -d \
-h rabbitmq-node2 \
-e TZ=Asia/Shanghai \
-e RABBITMQ_ERLANG_COOKIE='helloworld' \
-v $HOME/Docker/rabbitmq/conf/cluster-rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf \
-v $HOME/Docker/rabbitmq/data/node2:/var/lib/rabbitmq/mnesia:rw \
--add-host rabbitmq-node1:172.17.0.3 \
--add-host rabbitmq-node2:172.17.0.4 \
--add-host rabbitmq-node3:172.17.0.5 \
--name rabbitmq-node2 \
rabbitmq:3-management
docker run -d \
-h rabbitmq-node3 \
-e TZ=Asia/Shanghai \
-e RABBITMQ_ERLANG_COOKIE='helloworld' \
-v $HOME/Docker/rabbitmq/conf/cluster-rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf \
-v $HOME/Docker/rabbitmq/data/node3:/var/lib/rabbitmq/mnesia:rw \
--add-host rabbitmq-node1:172.17.0.3 \
--add-host rabbitmq-node2:172.17.0.4 \
--add-host rabbitmq-node3:172.17.0.5 \
--name rabbitmq-node3 \
rabbitmq:3-management这次启动的时候没有指定默认的用户和密码,会使用guest:guest用作默认的用户名和密码,并且在配置文件中指定了loopback_users.guest = false配置,能允许guest用户从任何网络地址登录(默认只允许从localhost登录)
客户端连接集群
不同的客户端可能有不同的支持,大多数客户端库支持接受列表参数来连接集群,如果一个节点失效,客户端可以重新连接另一个节点,恢复拓扑结构并继续操作。如果客户端不支持连接多个节点,可以为集群添加负载均衡,如haproxy,客户端只需要连接haproxy的代理地址即可。
haproxy 配置
配置文件haproxy.cfg:
global
maxconn 4000
user root
group root
log 127.0.0.1 local0
log 127.0.0.1 local1 notice
daemon
ca-base /etc/ssl/certs
crt-base /etc/ssl/private
ssl-default-bind-ciphers ECDH+AESGCM:DH+AESGCM:ECDH+AES256:DH+AES256:ECDH+AES128:DH+AES:ECDH+3DES:DH+3DES:RSA+AESGCM:RSA+AES:RSA+3DES:!aNULL:!MD5:!DSS
ssl-default-bind-options no-sslv3
defaults
log global
mode http
option dontlognull
timeout connect 5000
timeout client 50000
timeout server 50000
option httpclose
option httplog
option redispatch
timeout connect 10000
maxconn 60000
retries 3
errorfile 400 /usr/local/etc/haproxy/errors/400.http
errorfile 403 /usr/local/etc/haproxy/errors/403.http
errorfile 408 /usr/local/etc/haproxy/errors/408.http
errorfile 500 /usr/local/etc/haproxy/errors/500.http
errorfile 502 /usr/local/etc/haproxy/errors/502.http
errorfile 503 /usr/local/etc/haproxy/errors/503.http
errorfile 504 /usr/local/etc/haproxy/errors/504.http
listen http_front
bind 0.0.0.0:1080
stats refresh 30s
stats uri /haproxy?stats
stats realm Haproxy Manager
stats auth admin:admin
listen rabbitmq_admin
bind 0.0.0.0:15672
server rabbtmq-node1 172.17.0.3:15672
server rabbtmq-node2 172.17.0.4:15672
server rabbtmq-node3 172.17.0.5:15672
listen rabbitmq_cluster
bind 0.0.0.0:5672
option tcplog
mode tcp
timeout client 3h
timeout server 3h
option clitcpka
balance roundrobin
server rabbitmq-node1 172.17.0.3:5672 check inter 5s rise 2 fall 3
server rabbitmq-node2 172.17.0.4:5672 check inter 5s rise 2 fall 3
server rabbitmq-node3 172.17.0.5:5672 check inter 5s rise 2 fall 3启动haproxy容器:
docker run -d \
-v $HOME/Docker/haproxy/haproxy.cfg:/usr/local/etc/haproxy/haproxy.cfg:rw \
--name haproxy \
haproxy客户端连接示例,以python为例,连接只需设置haproxy的ip和端口:
#!/usr/bin/env python
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('172.17.0.6', 5672, credentials=pika.PlainCredentials('guest', 'guest')))
channel = connection.channel()
channel.queue_declare(queue='hello')
channel.basic_publish(
exchange='',
routing_key='hello',
body='Hello World!'
)
print(" [x] Sent 'Helllo World!'")
connection.close()重启节点
节点可以在任何时候加入集群和停止,即使节点崩溃也是可以的,两种情况下集群仍然可以继续工作,节点重新启动后,集群会自动将它加入。尝试停止rabbit节点:
rabbitmqctl stop_app查看集群状态:
root@rabbit-slave1:/# rabbitmqctl cluster_status
Cluster status of node 'rabbit@rabbit-slave1'
[{nodes,[{disc,[rabbit@rabbit,'rabbit@rabbit-slave1',
'rabbit@rabbit-slave2']}]},
{running_nodes,['rabbit@rabbit-slave2','rabbit@rabbit-slave1']},
{cluster_name,<<"rabbit@rabbit">>},
{partitions,[]},
{alarms,[{'rabbit@rabbit-slave2',[]},{'rabbit@rabbit-slave1',[]}]}]启动rabbit节点:
rabbitmqctl start_app再次查看集群状态:
root@rabbit-slave1:/# rabbitmqctl cluster_status
Cluster status of node 'rabbit@rabbit-slave1'
[{nodes,[{disc,[rabbit@rabbit,'rabbit@rabbit-slave1',
'rabbit@rabbit-slave2']}]},
{running_nodes,[rabbit@rabbit,'rabbit@rabbit-slave2','rabbit@rabbit-slave1']},
{cluster_name,<<"rabbit@rabbit">>},
{partitions,[]},
{alarms,[{rabbit@rabbit,[]},
{'rabbit@rabbit-slave2',[]},
{'rabbit@rabbit-slave1',[]}]}]
root@rabbit-slave1:/#可以看到rabbit节点自动加入了集群
删除节点
如果一个节点不再是集群的一部分,它需要被完全移除。例如移除rabbit节点,将它恢复成独立的服务。首先要停止 RabbitMQ 应用,重置节点,然后重启 RabbitMQ 应用。
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl start_app我们也可以远程移除一个节点,这是有用的,例如我们需要移除一个没有响应的节点。我们演示在rabbit-slave2上移除rabbit-slave1节点:
root@rabbit-slave1:/# rabbitmqctl stop_app
root@rabbit-slave2:/# rabbitmqctl forget_cluster_node rabbit@rabbit-slave1注意事项
该方法是通过修改容器的/etc/hosts文件来确保三个节点能够互相访问的,重启容器之后容器的/etc/hosts文件会刷新,因此集群节点的连接会失败,建议使用docker-compose,openshift之类的工具或平台。
当整个集群关闭时,最后关闭的节点应最先启动,如果不是,这个节点会等待30s让最后的硬盘节点启动,然后启动失败。如果最后一个关闭的节点无法被唤醒,它可以用forget_cluster_node命令从集群中移除。如果所有集群节点都以同时和不受控制的方式停止,可以在一个节点上使用force_boot命令使其再次可引导。

